

Are NVIDIA, Anthropic, and Google Hiding the Real AI?
The smoking gun is not in the demos. It is buried in the papers almost nobody reads.


From Conspiracy to Receipts
Yes, the title sounds like a conspiracy theory.
But let me say in plain words what they refuse to admit: they are trying to reach the moon by building a taller ladder, scaling flat transformers, throwing hundreds of billions of dollars a year in brute-force computation at a problem the architecture cannot solve at any cost.
Meanwhile they hide the blueprint they are actually working on, the rocket ship that is Geometric AI, which would save trillions by handing out the whole map instead of one street address at a time.
Of course they are telling you the opposite story. The core of it is much simpler than the trillion-dollar price tag suggests: at the heart of current AI sits a geometrical problem, and no GPU farm in the world is going to fix it, not even with the nuclear-powered data center the size of Patagonia they have started building.
Stay with me. Because you will see how this apparently crazy absurdity has a point of sanity hidden inside the labs themselves: their research teams are following a different approach to the sola computatione of the current AI church.
The smoking gun is neither a secret server farm nor a leaked memo. And least of all, it is not some cinematic superintelligence hidden behind a locked door. It is something much colder and more practical.
The back door is inside the technical and scientific papers of the companies themselves, which, except for some expert nerds, almost nobody outside the field reads.
Do you want to find out whether NVIDIA, Google, Anthropic, and the rest are selling the opposite of what they are intensively researching? Then don’t read their press releases, their stage-managed public events, or the effusive declarations of their CEOs. Do something far simpler: grab the research papers of their fringe teams, and you will see where this story begins and how it drives into a new territory of AI that should set off alarms for you.
Don’t worry. I have done the homework for you. Here we go.
We Should Already Have a Truly Non-Parroting AI
But first, let me be precise about what is under attack in current AI.
Ok, we have already mentioned transformers. Sure, they have positional encoding. They have attention. They mix each token with the tokens around it across many layers of computation. They are not blind to context in the trivial sense; anyone arguing that they are has not opened the 2017 paper.
The legitimate attack is not that AI is blind.
The legitimate attack is that the current architecture handles context in a structurally wrong way, and scaling computation cannot truly fix it.
Attention layered on top of flat embedding spaces does not, by itself, measure the semantic distance between concepts that overlap and shift with context.
Take justice and law as a worked example.
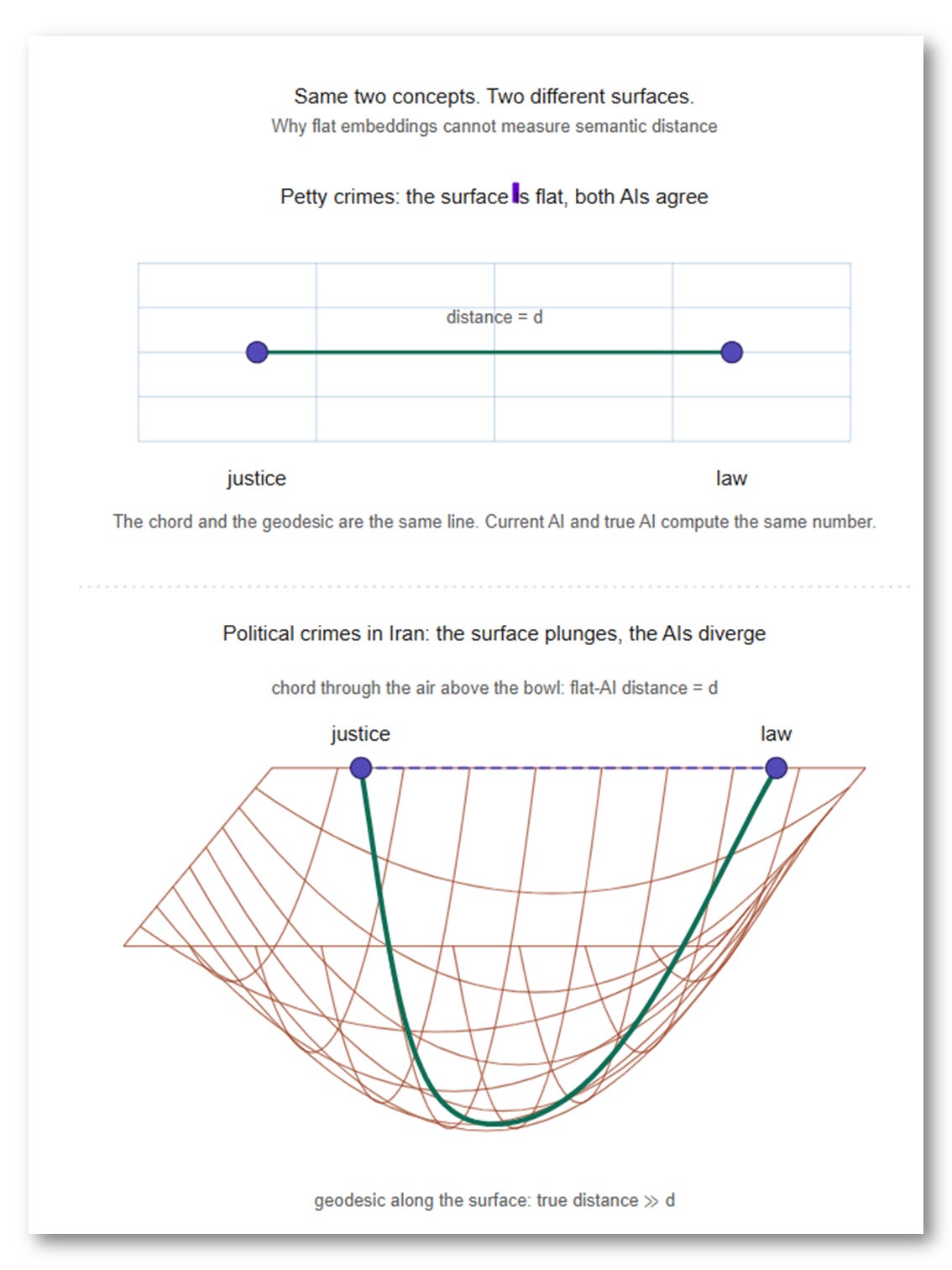
The distance between these two concepts in the democratic United States and in the theocracy of Iran may look almost identical when you are talking about petty crimes and ordinary civil offenses. But the moment you move to political crimes, the two concepts can sit at opposite ends of the semantic space.
Same two concepts, yeah, but…
Different distance.
Different context.
That is the point.
Meaning is not just a word sitting near another word. Meaning is a position inside a changing semantic terrain. The distance between concepts depends on the background against which they are read.
Flat AI embeddings cannot do this for free. They force the model to fake it by feeding it enough examples to memorize how the distance shifts: different regimes, different offenses, different legal traditions, endless combinations. Brute statistical memorization where geometry should be doing the work.
It is the flat-map problem one layer deeper. You cannot measure curved distances with a straight ruler, no matter how many rulers you stack. Context is not just another word the model processes. It is the ground the words sit on, the surface that decides what the distances between them mean. Flat AI keeps trying to do computation where it should be doing geometry, and no amount of training data can fix that.
It is like trying to measure speed with a stopwatch alone, ignoring distance. A stopwatch gives you time. A speedometer combines time and distance into one quantity — speed — that neither alone can give. Flat AI is the stopwatch (a functor: one input, one direction). Real cognition needs the speedometer (a profunctor: two inputs of different kinds, one a concept, the other its context).
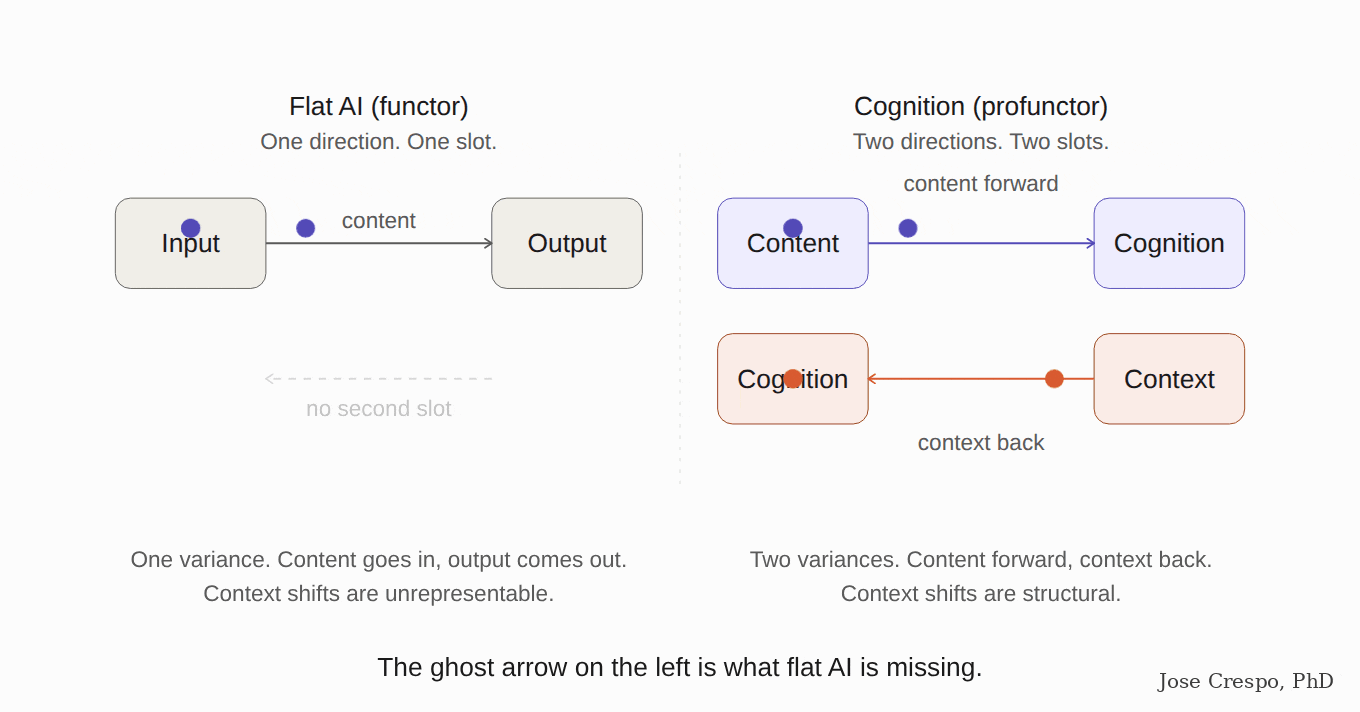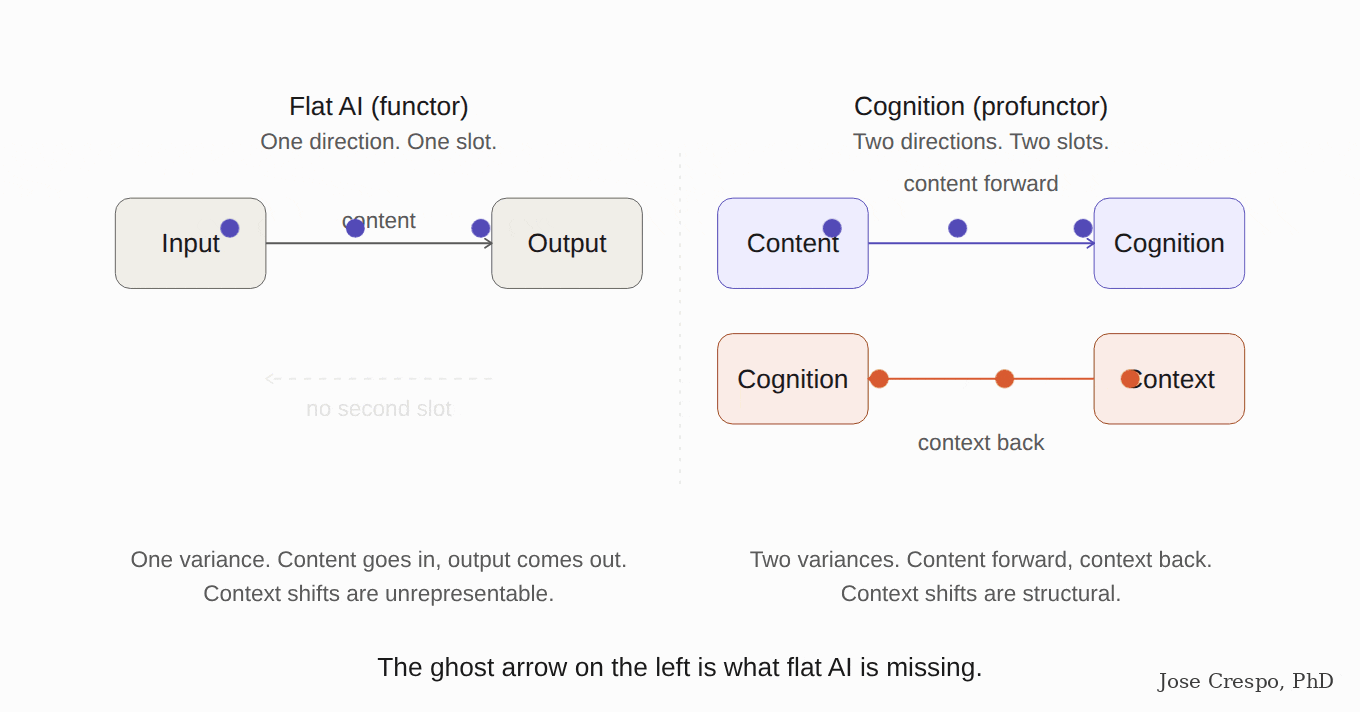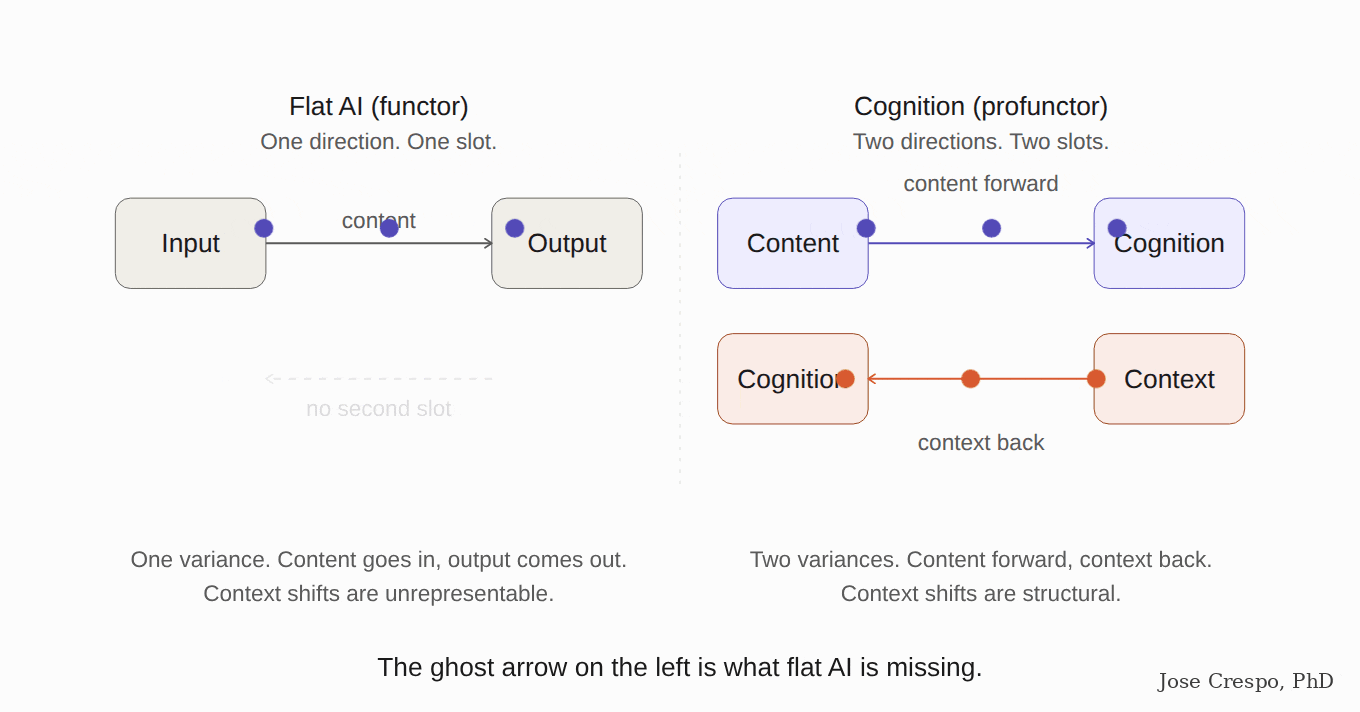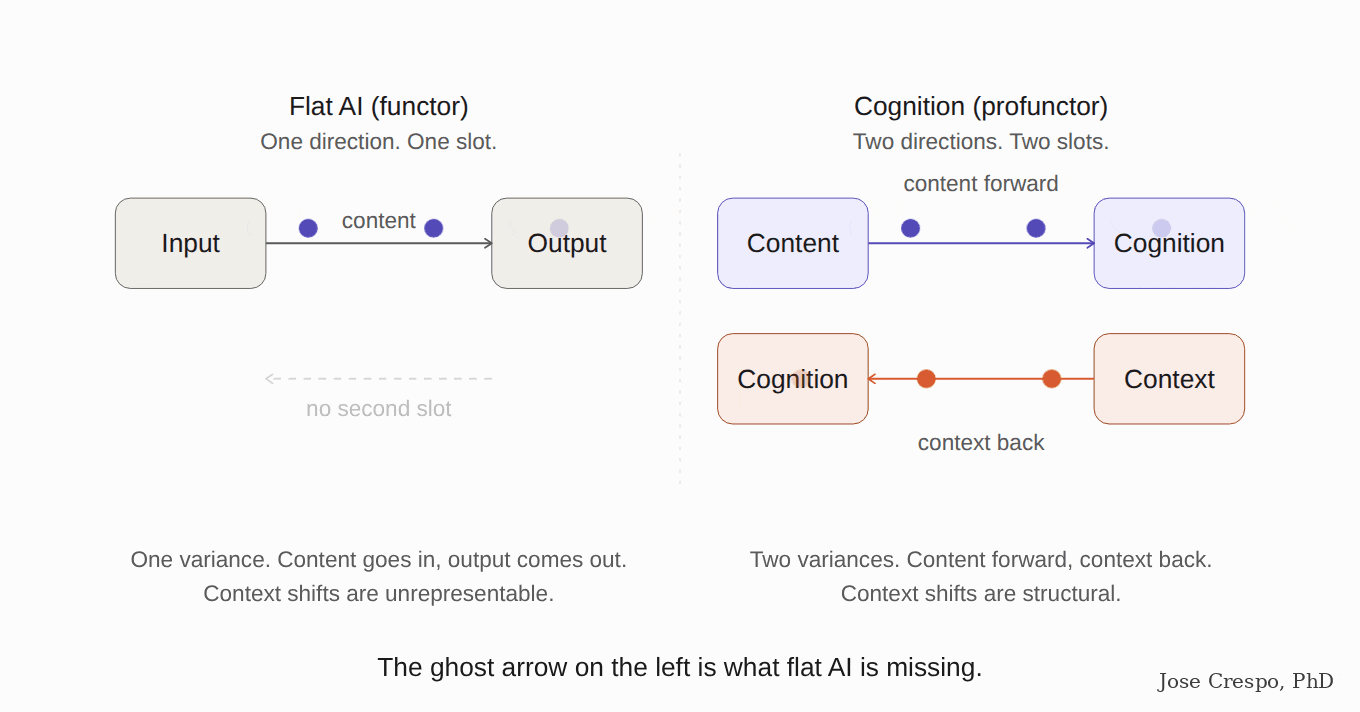
Their own papers are the smoking gun
This was only the warm-up. The mindblowing starts now. (1) Anthropic, caught red-handed. (2) Yale cracking open Llama 2, Gemma 2, DeepSeek-MoE. The curve they grew on their own. (3) Einstein as the working frame, not the metaphor. (4) The first blueprint of a new generation of thinking machines.
And much more...
Read A Mathematician Lurking in the TechUnderWorld: pure mathematics, animated proofs, analysis you will not find anywhere else on the web.