

Can Anthropic Really Read Their AI's Thoughts? Yes, but Only If They'd Done This Instead
Anthropic Read the Subtitles, Not the Thought, but the Real Reader Is Buildable

Beyond the Anthropic Hype
You know this movie. An AI lab’s marketing team announces that the model does not just look smart, it is really thinking, and as proof they show you a new toy (NLA, short for Natural Language Autoencoder, a second AI trained to describe the first one’s internal states in plain English) to photograph those thoughts.
That sounds like a serious cutting edge in AI research. But what did Anthropic actually build?
Just a stack of nested black boxes.
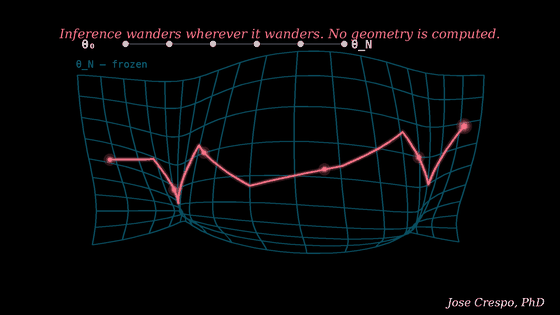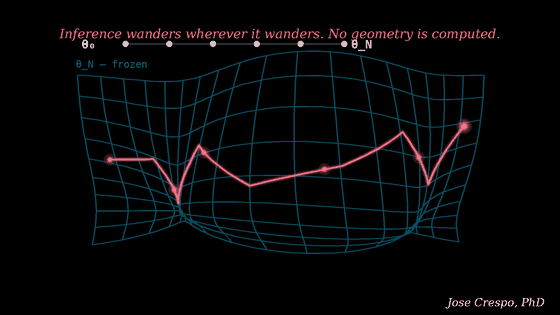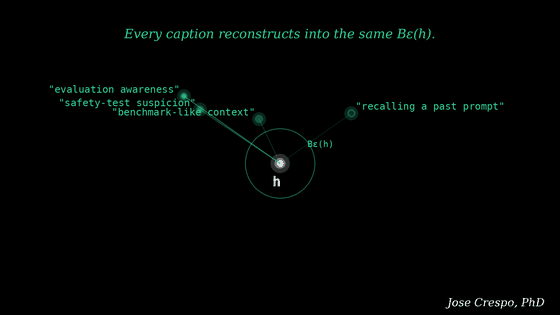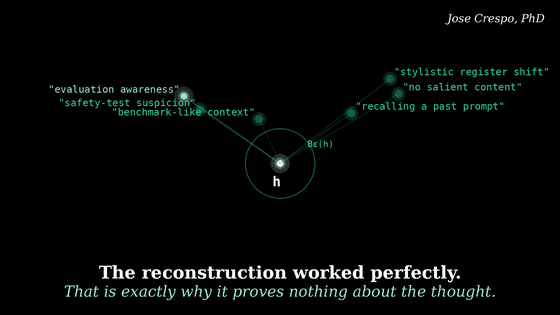
The first model produces internal numbers. The second model looks at those numbers and writes a caption. Then a third system tries to reconstruct the original numbers from that caption. If the reconstruction is close enough, the caption is treated as meaningful.
That is the machine. Something worth considering, yes, but certainly not the innovative leap that Anthropic’s marketing, and the many articles and posts spreading it afterward, try to suggest.
We know what Anthropic’s thought reader is not: it is neither a mind scanner nor a thought camera.
So before we follow the thought reader any further, we should stop at the source of its raw material: the numbers.

A language model does not think in words. It works with numerical states. At the simplest cartoon level, imagine one tiny unit receiving a few signals and assigning a weight to each one. Should I go to the party? Free pizza: strong positive signal. My ex will be there: strong negative signal. It is raining: another negative signal. Add the scores, pass the result forward, and move on.
That toy example is not a full transformer, of course. Real language models use real-valued vectors, attention, residual streams, nonlinear transformations, and many other moving parts. But the basic fact remains: words become numbers, those numbers are transformed through layer after layer, and eventually new numbers are turned back into words.
That is where activations enter the story.
An activation is not a hidden sentence inside the model. It is a snapshot of the machine mid-calculation. A frozen numerical state. Useful and informative, yes. But not readable in the way your diary is readable, or a confession is readable.
And that is exactly why Anthropic needs another AI to interpret it.
The first model produces the internal numerical pattern. The second model turns that pattern into a verbal caption. Then the system checks whether the labeled text caption preserves enough information to reconstruct something close to the original pattern of numbers.
That is all you need to know to conclude that, in fact, we did not find any thought inside the model. We found a smart reverse-engineering process, where the final AI in the chain analyzes the source AI’s internal numerical state and checks whether those text labels are consistent with the numbers they supposedly depict as internal thoughts.