

They Are Killing OpenAI, Google and Anthropic
Neural networks stop learning the moment training ends. A new breed of AI never stops. The math behind the overthrow.

The LLM Era Is Over
The biggest names in AI have an aging problem, and they are trying to fix it by throwing more raw computation at it. Blatant mistake!
OpenAI, Google, Anthropic, and the rest have spent the last two years scaling inference-time compute: chain-of-thought prompting, search trees, verification loops, more tokens at test time. As I argued in previous articles, this approach has eliminated most of the surface hallucinations, the kind that embarrass you in a demo, while producing deeper structural errors that are far harder to detect and far more dangerous to trust.
And here is what most people are missing: the new LLMs sound smarter. They are not. They have simply learned to hallucinate with better grammar. And the data proves it: with every new release, the deeper hallucination rates are going up, not down.
One of OpenAI’s biggest recent models hit an almost mind-blowing 50% hallucination rate on their own SimpleQA benchmark. One in two answers, fabricated. The coherency is a mask. What is underneath is getting worse.
So there you go: the companies that dominated the first era of AI are becoming its dinosaurs, and they are too busy scaling to notice what the new-kids-on-the-block competitors have already understood:
intelligence is not a frozen function. It is a continuously updated probability distribution moving through a structured space. And in a real learning system, space is not the stage on which computation performs. Space is part of the script.
In quieter times, this would be a technical debt problem. An expensive one, but manageable. These are not quiet times. The window is closing because the architecture itself is hitting a wall that compute cannot push through, and for the first time, there are credible alternatives waiting on the other side.
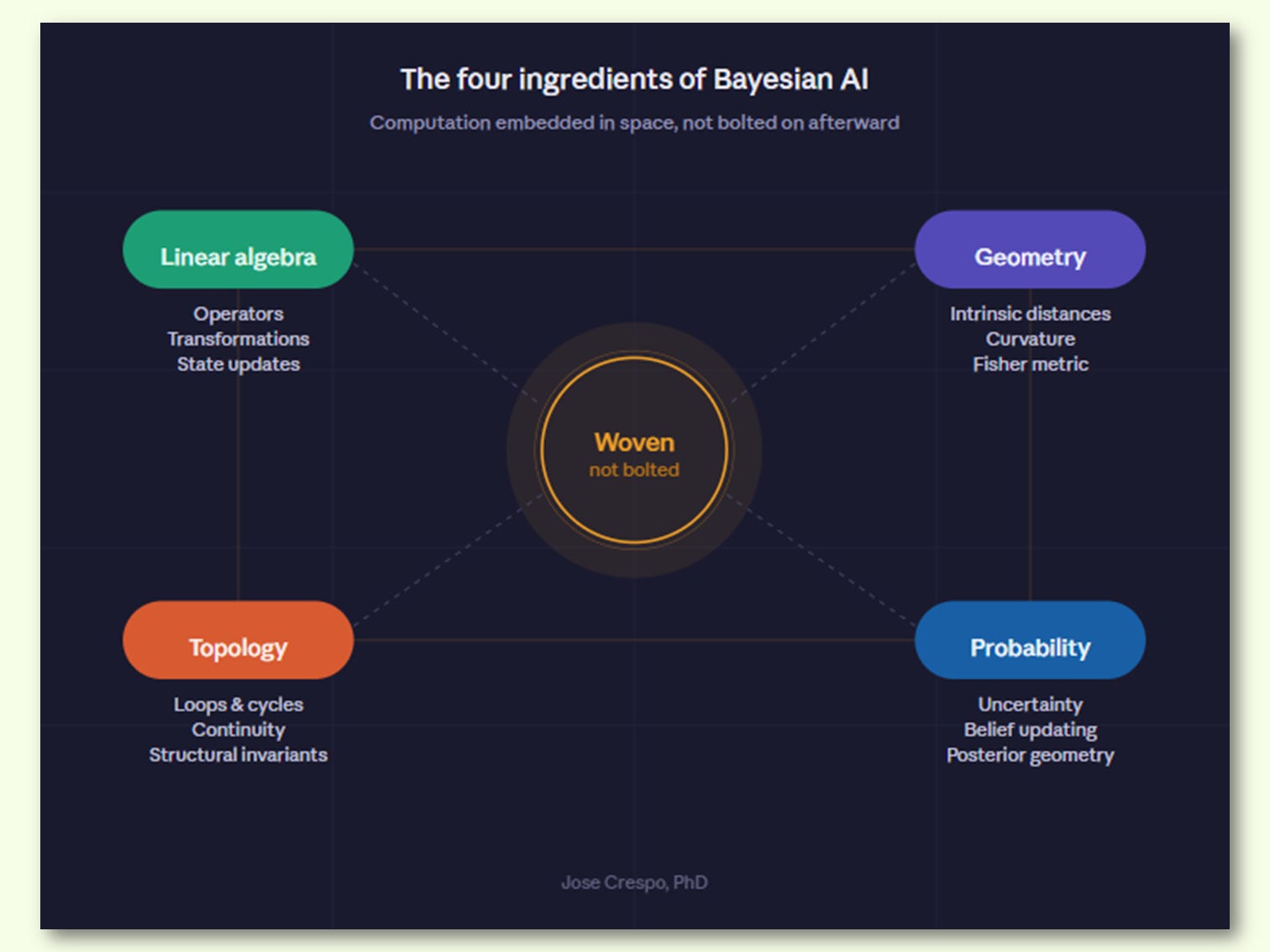
A new class of AI architecture is now positioned for a serious overtake of the entire industry. Not by building bigger transformers. Not by training longer. By changing the space in which computation happens. The approach has no single brand name yet, but the technical foundation is clear: Fisher-Bayesian AI (see chart above). It replaces the flat Euclidean geometry that neural networks have assumed since the 1980s with the curved, information-theoretic geometry that probability distributions actually live in. It does not improve the existing paradigm. It obsoletes the mathematical surface on which that paradigm was built.
Let’s cut now the tech jargon and explore with a real-world example in an animation with two drones facing the same landscape with the same obstacles. However, one runs on a frozen AI trained like an LLM: it planned its route once before deployment and never updates, because for the LLM AI the world stops changing the moment you finish training. The other runs on a Bayesian brain: every sensor reading reshapes its map of the real world (you know, the one with mountains, valleys, and the kind of surprises that don’t care about your training data) in real time. Now watch what happens when a new obstacle appears mid-flight.
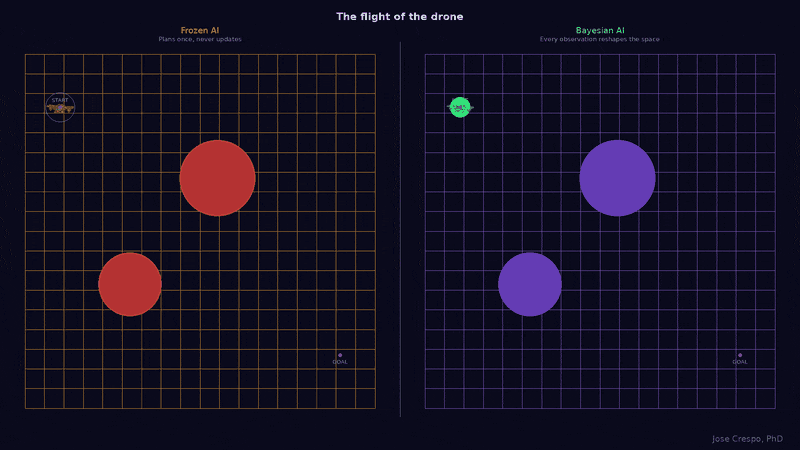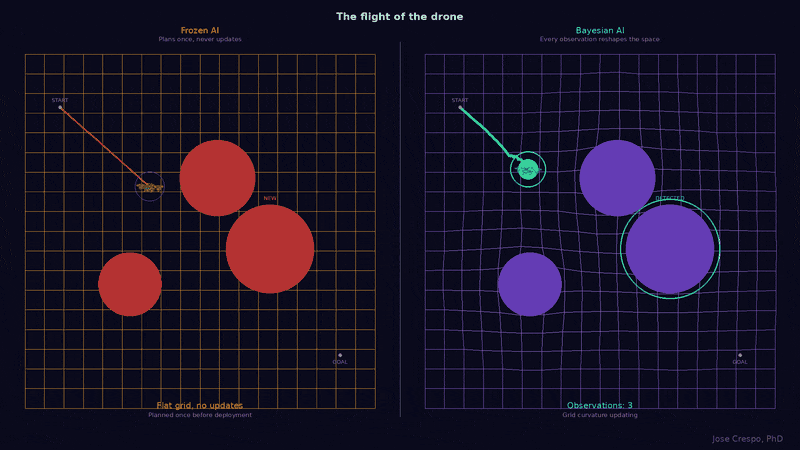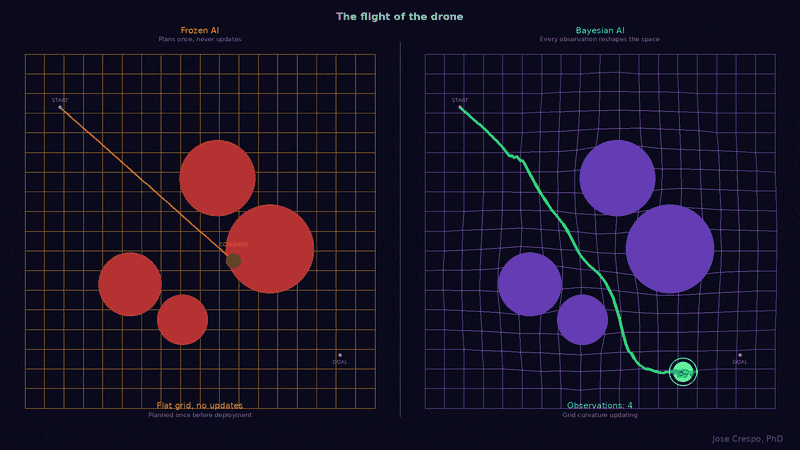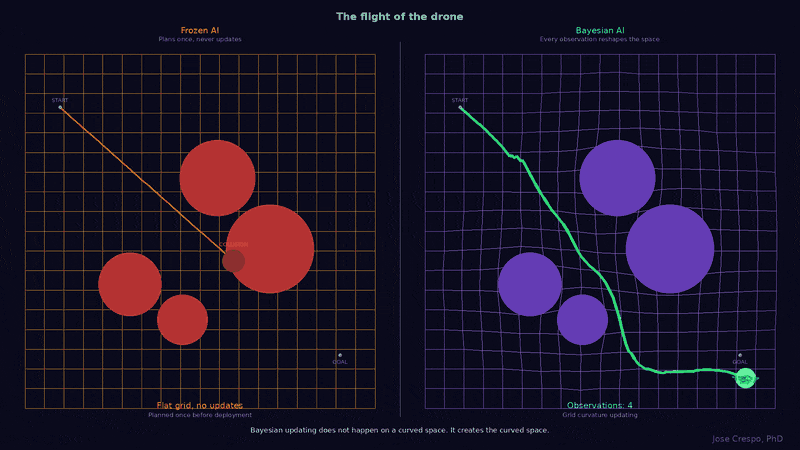
What follows is the proof: the names, the math, the battlefield map, and the animated visual arguments you will not find anywhere else. If you have read this far, you already know something is broken. The rest of this article shows you what replaces it.