

Everyone Bolted AI Together Wrong. One Shape Needs No Seams.
Flat vectors broke your model. The solenoid would fix it.


TL;DR (read this in 30 seconds)
Today’s LLMs store meaning in flat space (vectors). Flat space lets the model slide between nearby ideas too easily. That’s one reason it drifts and hallucinates.
The main solution to fragmentation is building a so-called unified map of meaning. Based on the currently developing AI toroid geometry, the most obvious and simplest solution is to use, inside the toroid, solenoid-style geometry that naturally combines:
(1) Memory phase (where we are in a thought loop),
(2) Taxonomy (what branch of meaning we’re in), and
(3) Path-dependence (the path you took changes what you know next).The math object is real; the AI claim is a testable hypothesis.
The development of this simplified technology will accelerate the evolution of today’s frustrating, limiting AI to the next level — the basic requirement for solid AGI: representation where semantic drift becomes expensive by design, not “fixed later by patches.”
Three concepts. You probably know them by different names

As Figure 1 shows, current AI treats these three concepts as separate engineering problems:
- different modules
- different geometries
- different code
Memory
Not RAM. We mean: what the model is currently carrying forward from the conversation. The cyan card in Figure 1— that circular arrow represents state that persists between turns. Current AI stores this as flat vectors. No phase. No structure. Just activation strength that fades.
Taxonomy
A fancy word for category tree.
Animal → cat → Persian cat.
Company → Apple → CEO → current CEO.
The purple card, that branching structure. Current AI handles this with hyperbolic geometry (Poincaré embeddings), completely separate from the memory system. Bolted on. Not unified.
Holonomy / path-dependence
Another fancy word for something you, if you’re a software developer, already know from debugging:
How you got here changes what happens next.
Same endpoint. Different route. Different state.
The orange card in Figure 1 shows it: two paths arrive at the same point, but they carry different histories. In LLM land: two chats can end with the same final question, but if one route wandered through Musk / SpaceX earlier, the model’s next answer can drift. Current AI? It ignores this entirely. No path memory. Just final position.
Memory. Taxonomy. Path-dependence. Current AI treats them as three separate engineering problems. That’s the mistake.
Look at Figure 1 one more time. Three cards. Three colors. Three separate systems. That fragmentation is the disease. The solenoid, added to the familiar toroidal geometry, is the cure.
The Geometry That Broke AI
Most LLMs store meaning as points in a huge vector space, like R^4096.
That sounds sophisticated. It is.
But it’s also… flat.
And flatness has a hidden cost:
In flat space, “nearby” often means “shares features,” not “is the same thing.”
In flat space, you can slide from one cluster to another without crossing a clear boundary.
That’s the thesis.
Not LLMs are dumb.
Not training data is bad.
The map is wrong.
Three failures of Flatland (use your programmer intuition)

Look at Figure 2. Three cards, three bugs you already know — even if you’ve never heard them described this way.
1) Collision (name clashes)
See the first card: two circles labeled river and money overlapping in the middle, with a confused “?” where they meet.
Bank = riverbank vs bank = finance.
In flat embeddings, those meanings drift close because the surrounding text patterns overlap. Rivers have banks. Money goes in banks. The word appears in similar sentence structures. So the vectors converge.
The model keeps guessing: which bank did you mean?
Translation: it’s doing runtime inference on every occurrence because the representation didn’t hard-separate the branches. The red overlap zone in Figure 2— that’s where your model lives, perpetually confused.
2) Spaghettification (state contamination)
The middle card shows it: a path that starts cyan (cooking), gets contaminated by nuclear, and ends red (physics?!).
You’re talking about cooking. Someone says nuclear family. Now the word nuclear is activated in the representation, not because you wanted it, but because it appeared.
Later, the model is one weak anchor away from drifting into nuclear physics🤪
Translation: the internal trajectory is like a messy global variable.
Once something enters the state, it can leak anywhere. The tangled line in Figure 2 isn’t artistic license: it’s what attention patterns actually look like when context bleeds across topics.
3) Hallucination zones (illegal intermediate states)
The third card makes it visual: two green checkmarks (valid ideas) connected by a path, but the middle is filled with red X marks (word salad).
Between two coherent ideas in flat space, there are countless in-between points that decode to nonsense.
Flat space says: Totally fine… it’s just linear interpolation.
Language says: Word salad.
That is hallucination geometry: legal movement through illegal meaning. The green endpoints in Figure 2 are real thoughts.
The red zone between them? That’s where hallucinations live.
And flat space has no fence keeping the model out.
The killer line at the bottom of Figure 2 says it all:
Flat space is too permissive. Not LLMs are dumb. Not training data is bad. The map is wrong.
These aren’t three separate bugs. They’re three symptoms of the same geometric disease: The typical flat, projected, multidimensional ℝ⁴⁰⁹⁶ doesn’t encode the constraints that language enforces. The space permits what meaning forbids.
The Extended Torus as an Alternative to AI Flat Space: Two Dials, One Surface
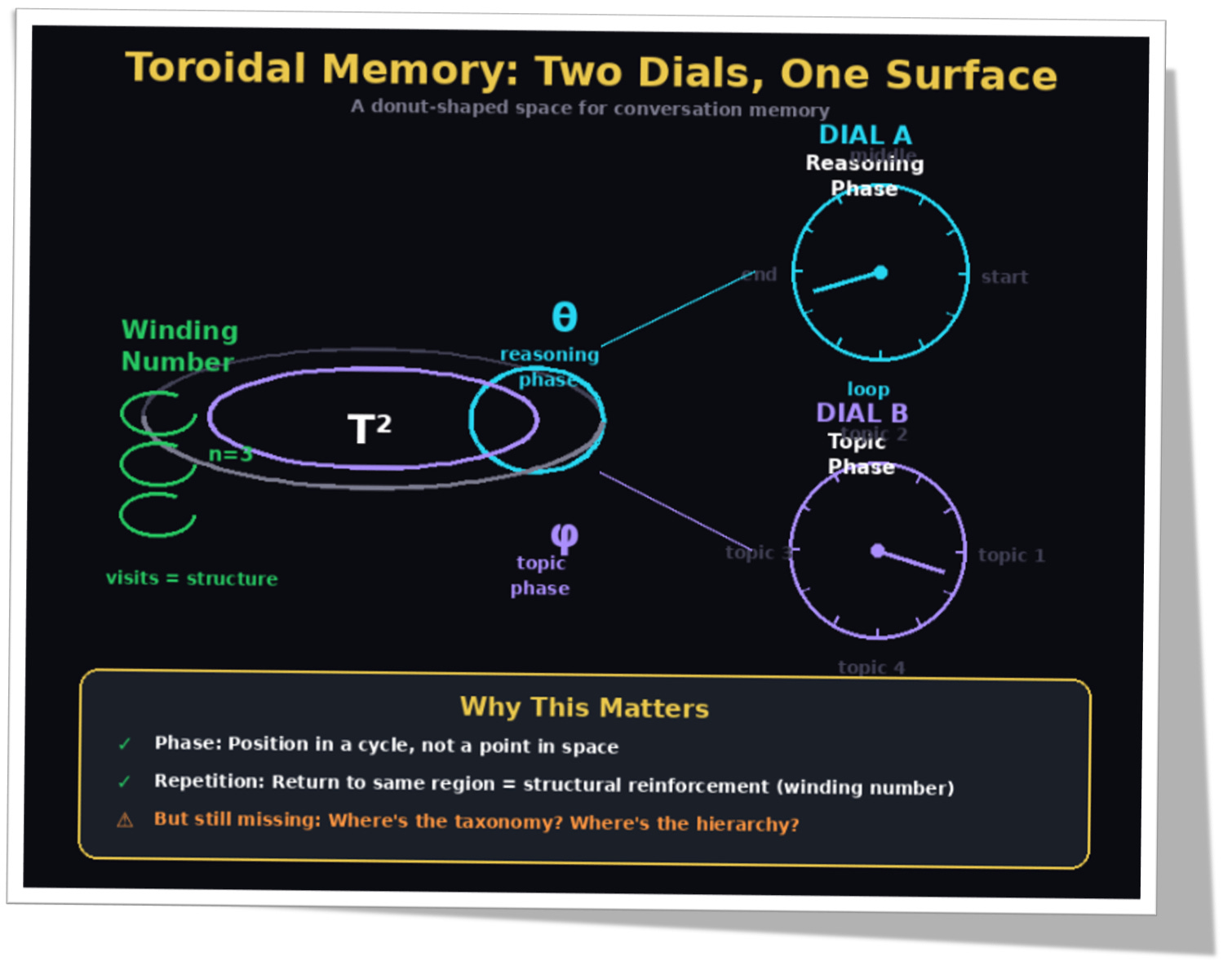
We previously proposed, together with other researchers, representing conversation memory on a torus: basically a donut shape.
You don’t need topology to get the point — see Figure 3 above. Just imagine two circular dials:
Dial A: reasoning phase (where we are in a thought loop)
Dial B: topic phase (which thread we’re currently on)
This matters because a torus gives you something flat space doesn’t: phase + repetition.
In flat space (which is what every current LLM uses) visiting the same region three times just makes the activation stronger. A bigger number. That’s it.
The geometry doesn’t know you came back. It doesn’t count loops.
This is why LLMs lose track. You can repeat a constraint five times in a prompt, and the model treats it as seems important, not stated five times, violated zero times. There’s no counter. Just weight.
On a torus, the geometry records when you loop back. That’s called a winding number: an integer that counts completed cycles.
Visit once? n=1.
Three times? n=3.
And unlike activation weights, this number can’t drift.
Why? Because it’s an integer, not a floating-point score. You can’t half-complete a loop.
You can’t slide from 3 to 2.7 to 2.
The winding number is what mathematicians call a topological invariant — a quantity unchanged by continuous deformation: Wiggle the path, stretch it, compress it, as long as you don’t cut it, the count stays fixed.
Integers are immune to drift. Floats aren’t.
Think about the difference:
The user has circled back to budget constraints 4 times → a fact
Budget seems important → a vibe
Current LLMs give you vibes. The torus gives you counts.
Repetition becomes structure, not just emphasis. But the torus is incomplete: it tracks where you are in the loop, not which branch you’re on. That missing piece is taxonomy.
The missing piece: how do we encode “branches”?
Phase answers: where am I in the loop?
But taxonomy asks: which branch am I even in?
Persian cat isn’t just cat with more features.
It’s cat → subtype.
The core issue: A good system should make it costly to jump from one identity branch to another unless the text truly demands it.
Flat space doesn’t.
So we need a geometry where branches are native.
The Solenoid: a donut with infinite nested depth
This is a candidate shape for unifying a fragmented AI.
Today’s language models don’t live inside one clean geometry.
They juggle half-separate spaces for memory, categories, and reasoning state, then stitch them together with heuristics inside a similarity space that behaves mostly flat (dot products, cosine, smooth interpolation).
A solenoid offers a different move: one compact geometry that carries three things at once, simply because of how it’s built (nested windings), not because we glued three modules together.
Phase: a built-in clock hand — where you are in the loop. (memory)
Branch: a built-in address — which track you’re on, and how deep. (classification/taxonomy)
Path: a built-in trip memory — how you got there still matters. (holonomy)
That coupling is the point: in a solenoid, cycle position and branch identity are not separate add-ons. They come as a package.
And that changes hallucinations.
It won’t abolish them in some absolute, philosophical sense. But it can kill the most common ones, the drift driven by collisions (different meanings sharing the same neighborhood) and spaghettification (too many near-parallel routes you can hop between for free).
In flat similarity space, branch switching is cheap: nearby is nearby, even when it’s the wrong nearby.
In a solenoid-like metric, branch identity and depth become part of distance. The deeper you commit, the more expensive it is to leave — not as a bolted-on penalty, but as a property of the geometry.
Watch the construction, it’s concrete, not a metaphor. A circle thickens into a torus; a winding wraps it; then a smaller wound copy nests inside; repeat… and the infinite limit is the solenoid. Every step is a concrete geometric operation. And the limit is precisely the kind of space where cycle position, branch address, and path-dependent state live together.

Now we’re on solid ground.
Not because this is mystical… because it’s structural.
The solenoid doesn’t give you a new trick.
It gives you a single representation where the three missing ingredients stop living in separate boxes:phase (where you are),
branch (which meaning-track you’re on),
path-dependence (how you got there).
One object. One metric. One state.
The secret math hack behind the solenoid: the p-adic address.
Inside this solenoid story lives Zp, the p-adic integers.
A p-adic number is like an infinite base-p digit string:
a0,a1,a2,a3,…
Read it as a path down a tree:
a0 chooses the main branch
a1 chooses the sub-branch
a2 refines again
And the distance between two addresses is basically:
How long do they share the same prefix before splitting?
Same first 5 digits? Very close.
Different first digit? Far.
That is taxonomy as an address system. No approximate tree embedding.
The tree behavior is built in.
A p=3 tree example:

Why This Could Reduce Drift (Bezos vs Musk Example)
CAT vs BEZOS? Trivial — first-digit split, maximally far.
Bezos vs Musk is harder. Same features: billionaire, tech founder, space company, media presence. Their vectors practically overlap.
So the model can silently slide:
Bezos → space company → Musk.
No alarm. No signal. Just a quiet interpolation through feature space. The model doesn’t know it changed subjects. It just… drifted.
Now watch what happens in a taxonomic address space.
Bezos and Musk are siblings — children of the same parent branch:
TECH BILLIONAIRE
├── BEZOS → Blue Origin
└── MUSK → SpaceXThey share a long prefix. They’re close. But they’re not the same node.
You can move between them — but it costs a branch change. You have to go up to the parent, then down to the sibling. That traversal is recorded. That cost becomes a signal.
So the model is less likely to drift unless the prompt demands a subject switch.
Flat space hides the switch. Taxonomy exposes it.
The GIF below shows the final branches where Bezos and Musk compete for attention:

How Attention Uses the Solenoid
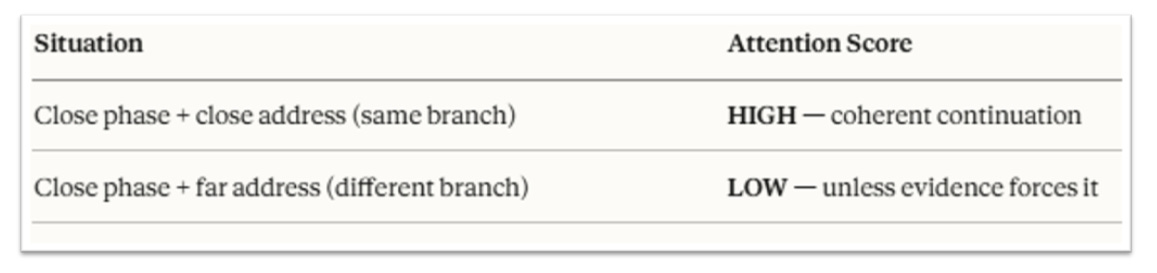
Figure 6 makes this concrete. Normal transformers ask one question: How similar is this token to that token?
You can keep that exact mechanism. You don’t rewrite the architecture. You just change what similar means.
Instead of dot product in ℝⁿ — which measures feature overlap — use a score that respects both the phase cycle and the taxonomic tree that the solenoid carries:
That’s it.
You don’t need to call it a Mercer kernel. You don’t need RKHS theory. You don’t need a PhD in functional analysis. For attention, you only need a scoring function that respects the solenoid’s structure.
And because phase and taxonomy live in the same geometry (not two spaces glued together) the score is natural.
You’re not reconciling incompatible distance metrics.
You’re measuring distance in one unified space (our familiar toroid geometry ) that already encodes both where am I in the reasoning cycle? and which branch of meaning am I on?
The design goal is simple:
Make incoherent jumps expensive. Make coherent continuation cheap.
The geometry does the rest.
Why Unification Is the Key
AGI isn’t a bigger LLM. It’s not more parameters, more data, more RLHF. Those are necessary but not sufficient.
AGI requires a unified representation: one where memory, meaning, and reasoning aren’t stitched together after the fact, but emerge from the same underlying structure.
The solenoid offers exactly this:
One geometry (not three bolted-together modules)
One space where phase, taxonomy, and path-dependence coexist
One representation where the failures that plague current AI become geometrically expensive instead of geometrically free
Reversibility in AI tracking: today’s LLMs have no undo. No checkpoint. No way to return to the moment before things went wrong. The solenoid changes that — not by magic, but by geometry:
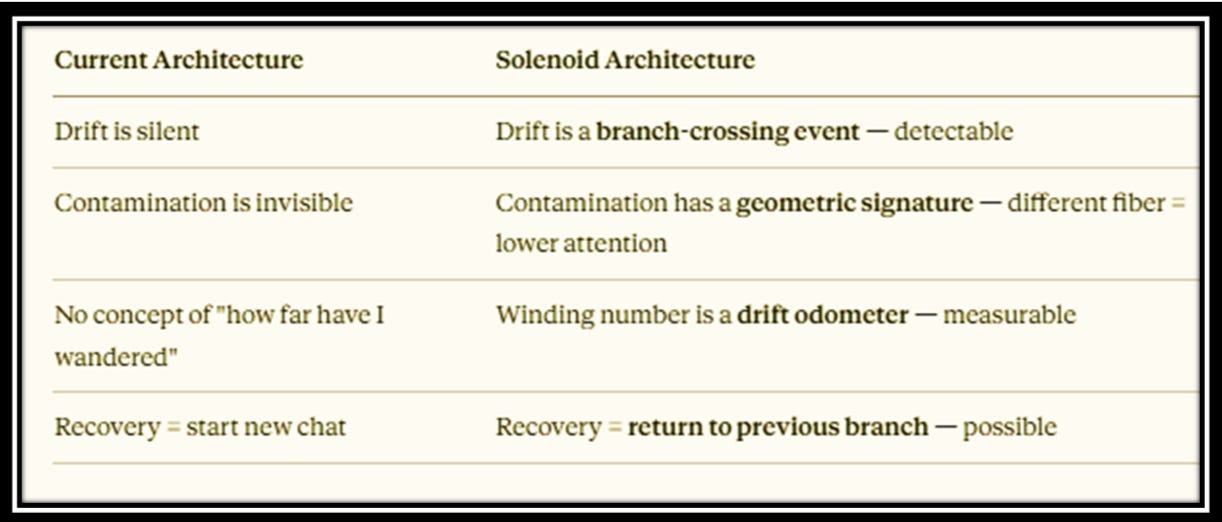
Drift becomes a detectable branch-crossing event. Contamination gets a geometric signature. The winding number becomes a drift odometer.
An intelligent system that can’t recover from errors isn’t intelligent — it’s brittle.
Human cognition doesn’t collapse when we notice we’ve gone off track.
We backtrack.
We revise.
We return to solid ground.
Any system worthy of the name general intelligence must do the same. The right geometry is the doorstep to AGI.
Thank you for writing this. I'm not a technical or math person, but I've got enough personal experience with these concepts to know that you're on to something.
What Id like to know is why aren't LLMs currently being developed in the way you've proposed here? Any ideas on that?
Thanks again for sharing your work Jose, you are the best writer on AI I have found so far. You're helping me and changing how I think!